Web crypto: moving forward
June 12, 2014I really appreciated Tim Bray’s post “Trusting browser code”. His
pragmatism resonated with me and Giulio Cesare. At Clipperz we’ve been dealing with the issue of secure Javascript code delivery since 2006, but this is still an open issue that is eventually attracting the attention of some bright minds.
This post is an effort to reaching out to the small community of people interested in web crypto in order to share ideas and perspectives.

(Photo of Tim Bray from AndroidGuys)
I don’t see anything here that’s really technically impossible. I hope I’m not missing anything, because the task of making Strong Privacy available to everyone is going to be way easier with decent browser crypto. - Tim Bray
Clipperz code delivery
Clipperz current approach to secure code delivery is far from being perfect and it basically consists of:
- delivering the whole Clipperz code with a single page load and a single HTML file that includes everything (HTML, JS, CSS, encoded images, …);
- designing Clipperz as a “single-page app” that does not automatically reload during user interaction with the application, nor does control transfer to another page.
Therefore anyone can verify that the code running in the browser is the merged and minified version of the verbose and multifile code stored on Github, provided they are able to perform the deterministic build process. And, of course, this can be done before entering the login credentials.
This is effective, but undoubtedly tricky, inconvenient and beyond the skills of the average user. How to improve from here? We are considering two different paths:
1. Running from a local file
The current single-page and single-file architecture can potentially allow Clipperz to run from a local file using the file URI scheme. This would give users the ability to download and verify the Clipperz code just the first time and then rely on the downloaded code. This would make the experience of using such a kind of web app comparable to using software clients or browser extensions. This “solution” creates what Tankred Hase call an “auditable static version” that can be signed, verified, reviewed.
However, as of today, it’s not a perfectly viable option due to restrictions imposed by browsers limiting the access to remote resources.
Moreover this is not a solution that could be adopted by all kinds of web apps, just the small fraction that share this peculiar architecture.
2. Implementing a Hash-URI scheme
This is a much more general approach and therefore much more complex.
The idea is to apply to the code of any web app (and backward to the code of libraries it relies upon) the solution described in this paper: Hash-URIs for Verifiable, Immutable, and Permanent Digital Artifacts(pdf).
Abstract - To make digital resources on the web verifiable, immutable, and permanent, we propose a technique to include cryptographic hash values in URIs. [..] Digital resources can be identified not only on the byte level but on more abstract levels, which means that resources keep their hash values even when presented in a different format.
Such technique would include cryptographic hash values in the URIs of all resources composing the web app. Each resource (e.g. the HTML main page of a web app) can be univocally identified by its URI and all linked resources (JS files, images, …) are addressed using similar hash-URI links.
Any hash-URI in a way “contains” the complete backwards history. In this sense, the “range of verifiability” of a resource with a hash-URI is not just the resource itself, but the complete reference tree obtained by recursively following all contained hash-URIs of other resources.
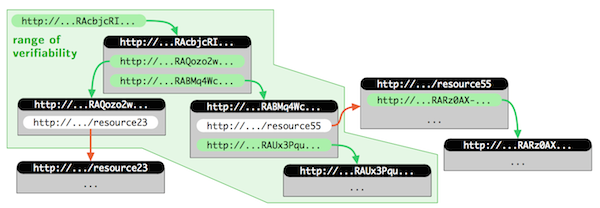
Your turn
I’m sure many out there have valuable inputs to provide, especially among those that have been playing with browser crypto for years, no matter the criticisms. Yes, I’m talking to you Tankred, Thomas, Nadim, Yiorgis… Share your thoughts!
(Tim Bray photos from AndroidGuys)
 Mastodon
Mastodon GitHub
GitHub Twitter
Twitter Google
forum
Google
forum